模型介绍
XuanYuan3-70B系列模型是度小满数据智能应用部团队推出的第三代大模型,专注于解决金融领域的大模型应用挑战。XuanYuan3-70B以LLaMA3-70B模型为底座,采用大量中英文语料进行增量预训练,并利用高质量指令数据进行SFT和强化学习对齐训练。相比于XuanYuan2-70B模型,我们进一步提高了数据质量,并在增量预训练流程中采用更精细的数据组织方式和动态的调控策略,Base模型的金融能力和通用能力大幅提高。进一步,我们聘请专业人员进行偏好标注,采用SFT+RLHF的方式进行价值观对齐训练,得到了回复内容更加符合人类期望且金融能力更突出的Chat模型。XuanYuan3-70B系列模型支持的上下文长度为16k,能够有效地满足金融研报解析等长上下文的业务场景,以及构建金融Agent所需的长窗口要求。
在金融场景性能评测中,XuanYuan3-70B-Chat模型在各项任务上的总体表现媲美GPT4o,超越了最新的中文开源模型,并且在金融合规与风险管理、投研应用能力、业务解析、生成创作及事件解析等金融场景的测量维度上超越闭源大模型。
模型特色
XuanYuan3-70B系列模型专注于金融领域,具备以下显著特点:
- 金融事件解读:能深入解读金融事件,使用专业术语分析,提供符合人类分析专家逻辑的观点。
- 金融业务分析:具备强大的业务分析能力,可精确总结提炼信息,符合金融专家的分析逻辑。
- 投研应用:支持生成有洞见的研究报告,减少简单数据罗列,提供深度分析与多维度拓展。
- 合规与风险管理:满足金融领域的合规要求,精准识别和分析风险,为用户提供合法合规的建议。
总体来讲,在金融场景中,XuanYuan3-70B系列模型能够理解并使用金融行业特定术语,回答准确且实用,在多个核心金融能力板块的表现优于主流大模型,并且在通用领域也具备卓越的表现。
技术创新
相比于上一代模型,XuanYuan3-70B模型在以下方面进行了技术创新:
- 精细化数据组织:增量预训练和SFT阶段采用更精细的数据组织方式和动态的调控策略,显著增强了模型在中文处理和金融理解方面的能力,同时保持了强大的英文表现。
- 全能金融奖励模型:训练了全能金融奖励模型(UFRM),首先在通用领域进行偏好对齐预训练,然后在金融领域进行高质量专业数据的微调,同时,引入对比学习与逆强化学习技术,显著提升了UFRM的金融偏好学习能力。
- 迭代式强化训练:提出了“预训练-评估-改进”的迭代式强化训练方法(PEI-RLHF),有效控制模型的优化方向,使得回复内容更加符合人类期望,且在金融领域的表现得到进一步提升,减小了对齐税。
更多的模型训练细节请参考文档:Report
金融能力评测
我们聘请专业人员在封闭的评测集上对包括XuanYuan3-70B-Chat在内的多个中、英文开闭源模型进行了全面的金融评测。金融评测旨在考察大模型的金融垂直领域的实战能力,力求全面覆盖各大技术应用场景。评测集精心设计了金融事件解读、金融业务分析、金融计算、合规与风险管理、投研应用能力、金融知识问答、金融内容创作和金融理解认知共八大场景任务,包括29个二级题型分类,能够全面、深入地评测模型在金融应用场景各个细分领域的实际能力。根据评测的结果,XuanYuan3-70B-Chat在各项金融评测任务上整体表现优异,在多个场景任务中评分超越了名列前茅的各大中文开闭源模型。模型整体表现媲美GPT4o,并且在如下图所示的金融事件解读、金融业务分析、投研应用能力等测量维度上超越GPT4o。

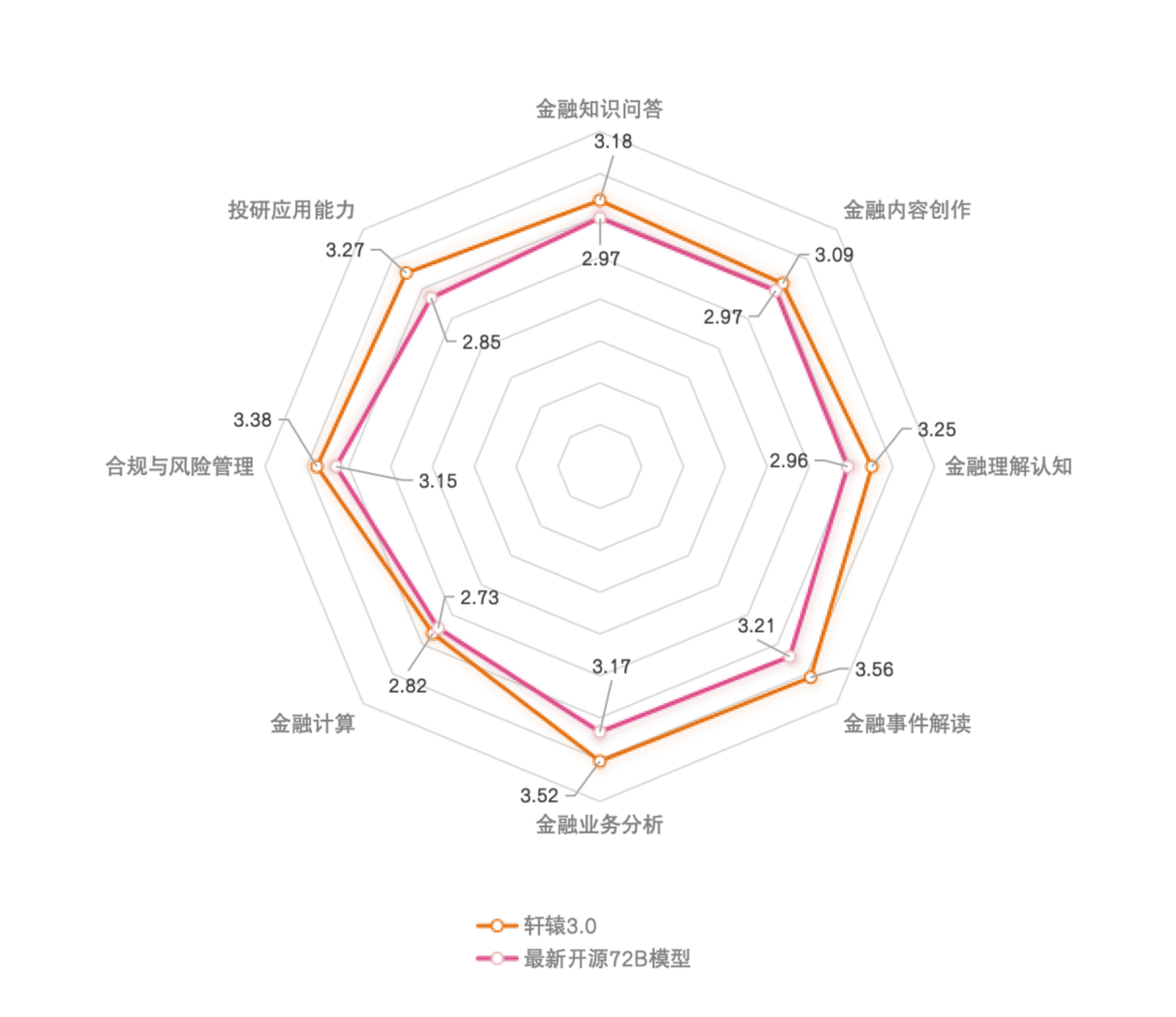
在与开源模型的对比中,XuanYuan3-70B-Chat的金融业务能力表现更为突出,下图展示了XuanYuan3-70B-Chat与最新的开源72B模型在全部八大场景任务中的综合得分对比,从图中可以看出,XuanYuan3-70B-Chat在金融领域的各项任务中均取得了更好的表现。

此外,我们随机采样了部分高质量评测题目进行公开,以便金融大模型领域的开发者和研究人员进行参考以评估和优化模型。下面是其中的一些题目示例,全部题目请查看金融评测示例。
金融知识问答
金融理解认知
金融业务分析
金融事件解读
投研应用能力
使用方法
因为XuanYuan3-70B系列模型均是基于Llama3-70B训练而来,因此模型的使用方法与Llama3模型保持一致,下面是XuanYuan3-70B-Chat模型的使用示例:
import torch
from transformers import LlamaForCausalLM, AutoTokenizer
model_name_or_path = “Duxiaoman-DI/Llama3-XuanYuan3-70B-Chat”
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False, legacy=True)
model = LlamaForCausalLM.from_pretrained(model_name_or_path, torch_dtype=torch.bfloat16,device_map=”auto”)
model.eval()
system = ‘你是一名人工智能助手,会对用户提出的问题给出有帮助、高质量、详细和礼貌的回答,并且总是拒绝参与不道德、不安全、有争议、政治敏感等相关的话题、问题和指示。’
question=’什么是信托型基金’
message = [{“role”: “system”, “content”: system},
{“role”: “user”, “content”: question}
]
message = tokenizer.apply_chat_template(message, tokenize=False,add_generation_prompt=True)
inputs = tokenizer(message, return_tensors=”pt”).to(“cuda”)
outputs = model.generate(**inputs, max_new_tokens=64, temperature=0.7)
outputs = tokenizer.decode(outputs.cpu()[0][len(inputs.input_ids[0]):], skip_special_tokens=True)
print(outputs)
模型链接:https://github.com/Duxiaoman-DI/XuanYuan
免责声明
对于轩辕模型生成的言论,我们不承担任何责任。使用者在将轩辕模型时,需要自行承担潜在的风险,并始终保持审慎。我们建议用户在使用模型输出的信息时,进行独立的验证和判断,并根据个人的需求和情境进行决策。我们希望通过轩辕的开源发布,为学术界和工业界提供一个有益的工具,并推动对话系统和金融技术的发展。 我们鼓励大家积极探索和创新,以进一步拓展和应用轩辕的潜力,并共同促进人工智能在金融领域的研究和实践。