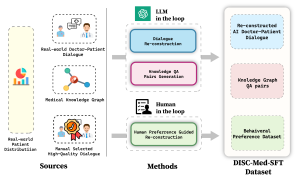
本项目基于Mistral发布的模型Mixtral-8x7B进行了中文扩词表增量预训练,希望进一步促进中文自然语言处理社区对MoE模型的研究。我们扩充后的词表显著提高了模型对中文的编解码效率,并通过大规模开源语料对扩词表模型进行增量预训练,使模型具备了强大的中文生成和理解能力。
项目开源内容:
- 中文Mixtral-8x7B扩词表大模型
- 扩词表增量预训练代码
请注意,Chinese-Mixtral-8x7B仍然可能生成包含事实性错误的误导性回复或包含偏见/歧视的有害内容,请谨慎鉴别和使用生成的内容,请勿将生成的有害内容传播至互联网。
模型综合能力
我们分别使用以下评测数据集对Chinese-Mixtral-8x7B进行评测:
- C-Eval:一个全面的中文基础模型评估套件。它包含了13948个多项选择题,涵盖了52个不同的学科和四个难度级别。
- CMMLU:一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力,涵盖了从基础学科到高级专业水平的67个主题。
- MMLU:一个包含57个多选任务的英文评测数据集,涵盖了初等数学、美国历史、计算机科学、法律等,难度覆盖高中水平到专家水平,是目前主流的LLM评测数据集之一。
- HellaSwag:一个极具挑战的英文NLI评测数据集,每一个问题都需要对上下文进行深入理解,而不能基于常识进行回答。
根据Mistral发布的技术报告,Mixtral-8x7B在推理时将激活13B参数。下表为Chinese-Mixtral-8x7B与其他13B规模的中文扩词表模型在各个评测数据集上的5-shot结果:
模型名称 增量训练语料 C-Eval
(中文)CMMLU
(中文)MMLU
(英文)HellaSwag
(英文)IDEA-CCNL/Ziya2-13B-Base 650B Token 59.29 60.93 59.86 58.90 TigerResearch/tigerbot-13b-base-v3 500B Token 50.52 51.65 53.46 59.16 Linly-AI/Chinese-LLaMA-2-13B-hf 11B Token 42.57 41.95 51.32 59.05 hfl/chinese-llama-2-13b 约30B Token(120GB) 41.90 42.08 51.92 59.28 Chinese-Mixtral-8x7B(本项目) 42B Token 52.08 51.08 69.80 65.69 在中文知识和理解方面,我们的Chinese-Mixtral-8x7B与TigerBot-13B-Base-v3性能相当。由于Chinese-Mixtral-8x7B的训练数据量仅为TigerBot-13B-Base-v3的8%,我们的模型仍有进一步提升的空间。与此同时,得益于原版Mixtral-8x7B模型强大的性能,我们的Chinese-Mixtral-8x7B达到了各个扩词表模型的最强英文水平。
由于不同版本的评测脚本实现细节有细微差异,为了保证评测结果的一致性和公平性,我们的评测脚本统一使用EleutherAI发布的lm-evaluation-harness,commit hash为28ec7fa。
模型生成效果
下表为各个扩词表模型的生成效果。由于部分模型的预训练语料未使用
eos_token进行分隔,我们采用了max_tokens = 100对生成文本进行截断。我们的采样参数为temperature = 0.8, top_p = 0.9。
中文编解码效率
针对中文编解码效率,我们使用各个扩词表模型的分词器对SkyPile数据集的一个切片(2023-06_zh_head_0000.jsonl)进行编码,对比了各个分词器输出的中文文本Token量:
模型名称 模型类别 词表大小 中文文本Token量 编解码效率 meta-llama/Llama-2-13B-hf LLaMA 32000 780M 低 mistralai/Mixtral-8x7B-v0.1 Mixtral 32000 606M 低 Linly-AI/Chinese-LLaMA-2-13B-hf LLaMA 40076 532M 中 IDEA-CCNL/Ziya2-13B-Base LLaMA 39424 532M 中 hfl/chinese-llama-2-13b LLaMA 55296 365M 高 TigerResearch/tigerbot-13b-base-v3 LLaMA 65112 342M 高 Chinese-Mixtral-8x7B(本项目) Mixtral 57000 355M 高 在约1.4GB的测试文本中,我们的Chinese-Mixtral-8x7B中文编解码效率仅次于TigerBot-13B-Base-v3,较原模型提高了41.5%。这有利于加速中文文本的推理速度,并在In-Context Learning、Chain-of-Thought等场景中节省序列长度,有利于提高复杂推理任务的性能。